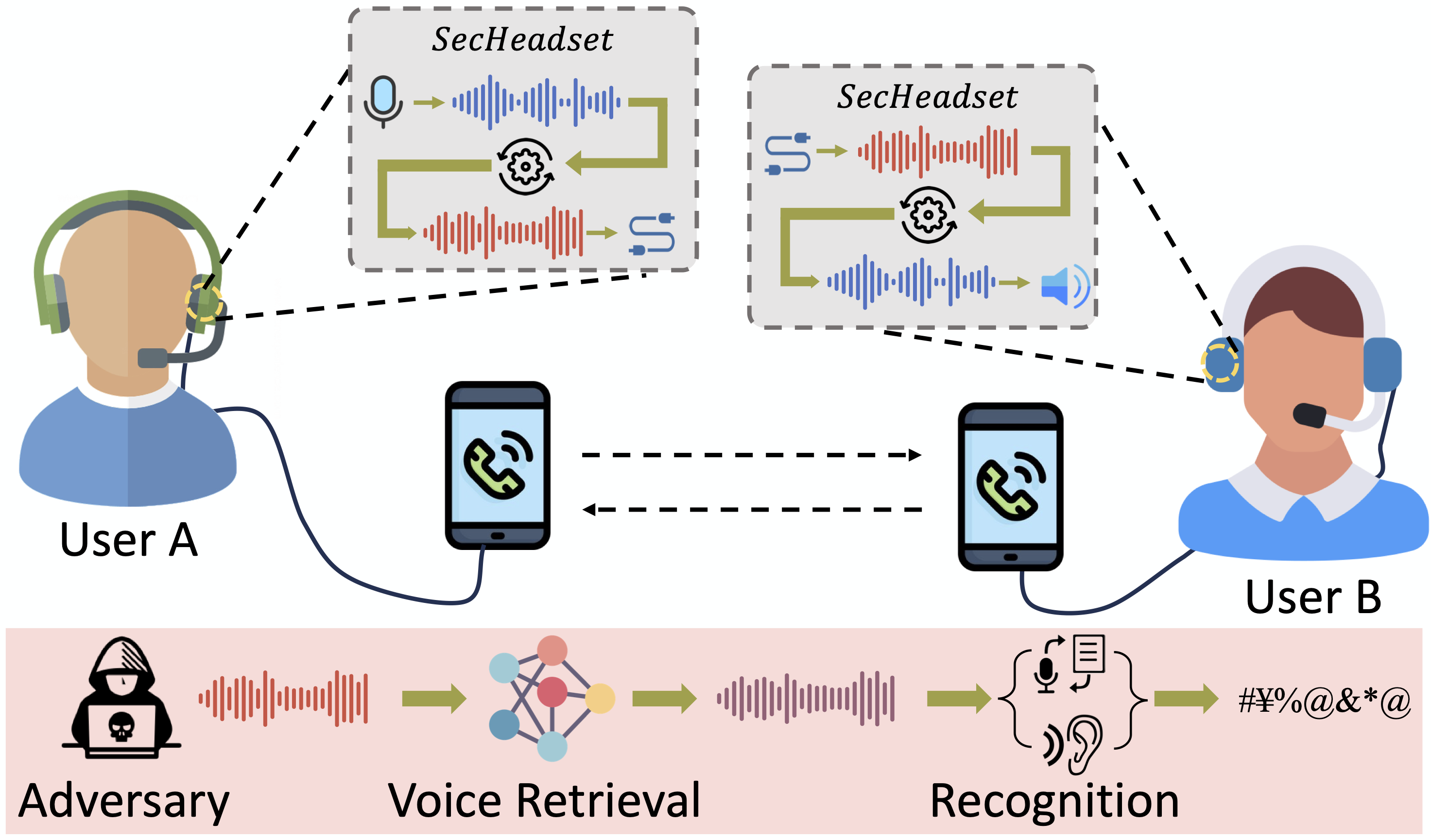
SecHeadset is a practical, plug-and-play, and end-to-end privacy protection hardware system for real-time voice communication. It can prevent any entities other than the two communication parties from eavesdropping on the communication. SecHeadset is compatible with various VoIP applications, such as Telegram, Skype, and WhatsApp. It is also compatible with different communication types, such as VoIP and voice message.
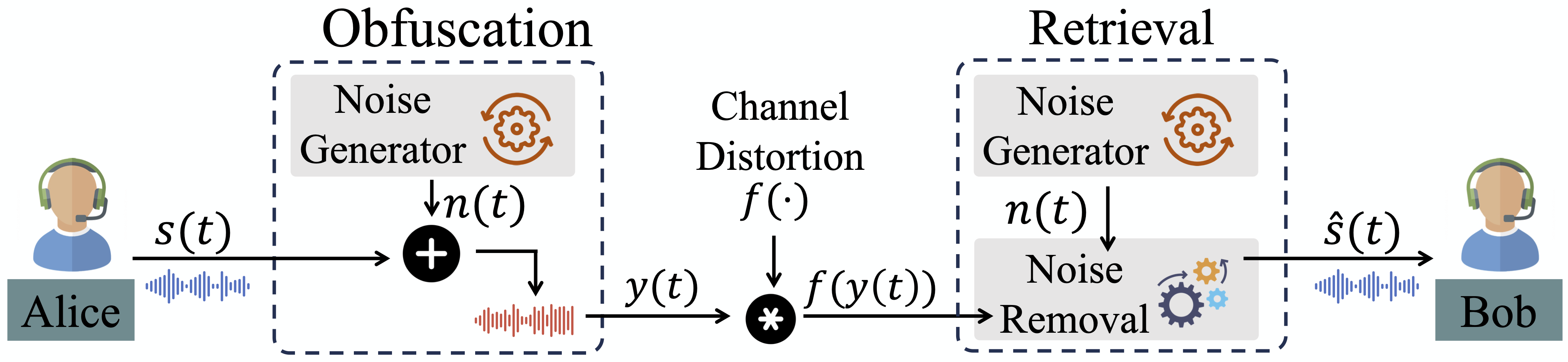
SecHeadset works as an audio relay between users and the communication device. The basic idea is to obfuscate user's voice before sending it to the communication device. In the receiver side, SecHeadset first retrieve the clean audio from the obfuscated audio and then plays it back to users. Specifically, we add phoneme-based noises to the voice for obfuscation. This type of noise has characteristics similar to human voice, which makes it robust to existing deep learning-based denoising techniques.
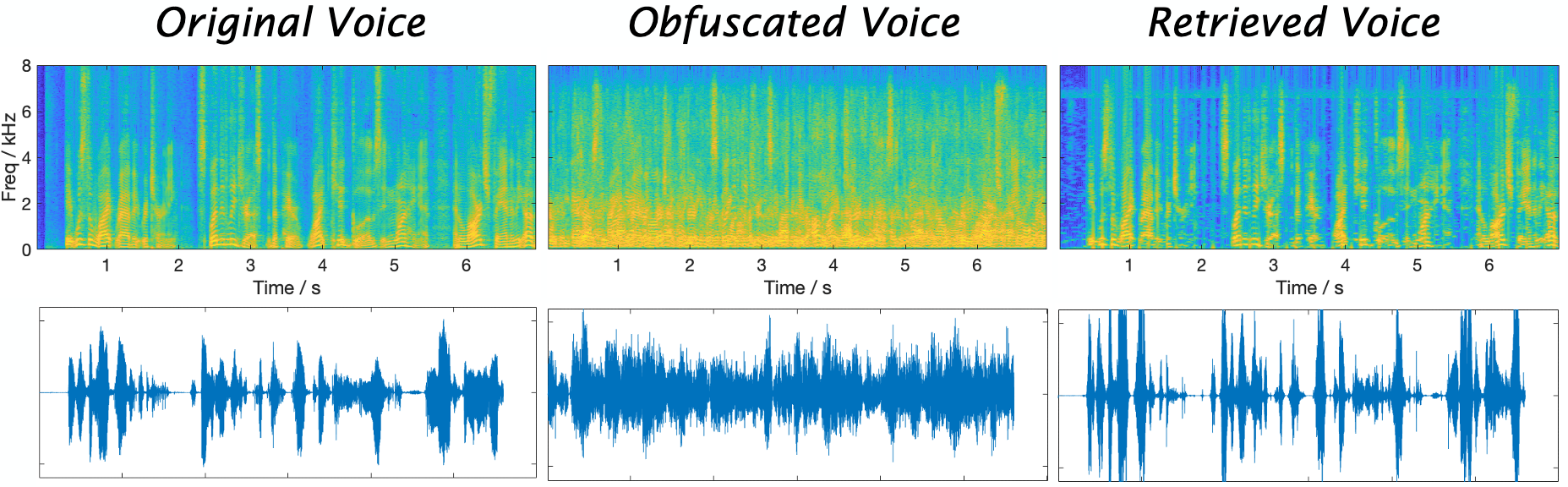
The following figure illustrates the spectrum and the time domain signal of the original, the obfuscated, and the retrieved voices processed by SecHeadset.
| Applications | 260-123440-0002 | 1188-133604-0015 | 3570-5696-0000 | 3575-170457-0024 |
| Skype | ||||
| Telegram | ||||
| Viber | ||||
| Messenger | ||||
| Line | ||||
| DingTalk |
The original audios are sampled from the test-clean subset of LibriSpeech
| Applications | 260-123440-0002 | 1188-133604-0015 | 3570-5696-0000 | 3575-170457-0024 |
| Skype | ||||
| Telegram | ||||
| Viber | ||||
| Messenger | ||||
| Line | ||||
| DingTalk |
| Applications | 260-123440-0002 | 1188-133604-0015 | 3570-5696-0000 | 3575-170457-0024 |
| Skype | ||||
| Telegram | ||||
| Viber | ||||
| Messenger | ||||
| Line | ||||
| DingTalk | ||||
| Bandwith | 260-123440-0002 | 1188-133604-0015 | 3570-5696-0000 | 3575-170457-0024 |
| 1 mbps | ||||
| 500 kbps | ||||
| 100 kbps | ||||
| 60 kbps |
| SNR | 260-123440-0002 | 1188-133604-0015 | 3570-5696-0000 | 3575-170457-0024 |
| -2 | ||||
| -4 | ||||
| -6 | ||||
| -8 | ||||
| -9 | ||||
| -10 | ||||
| -12 |
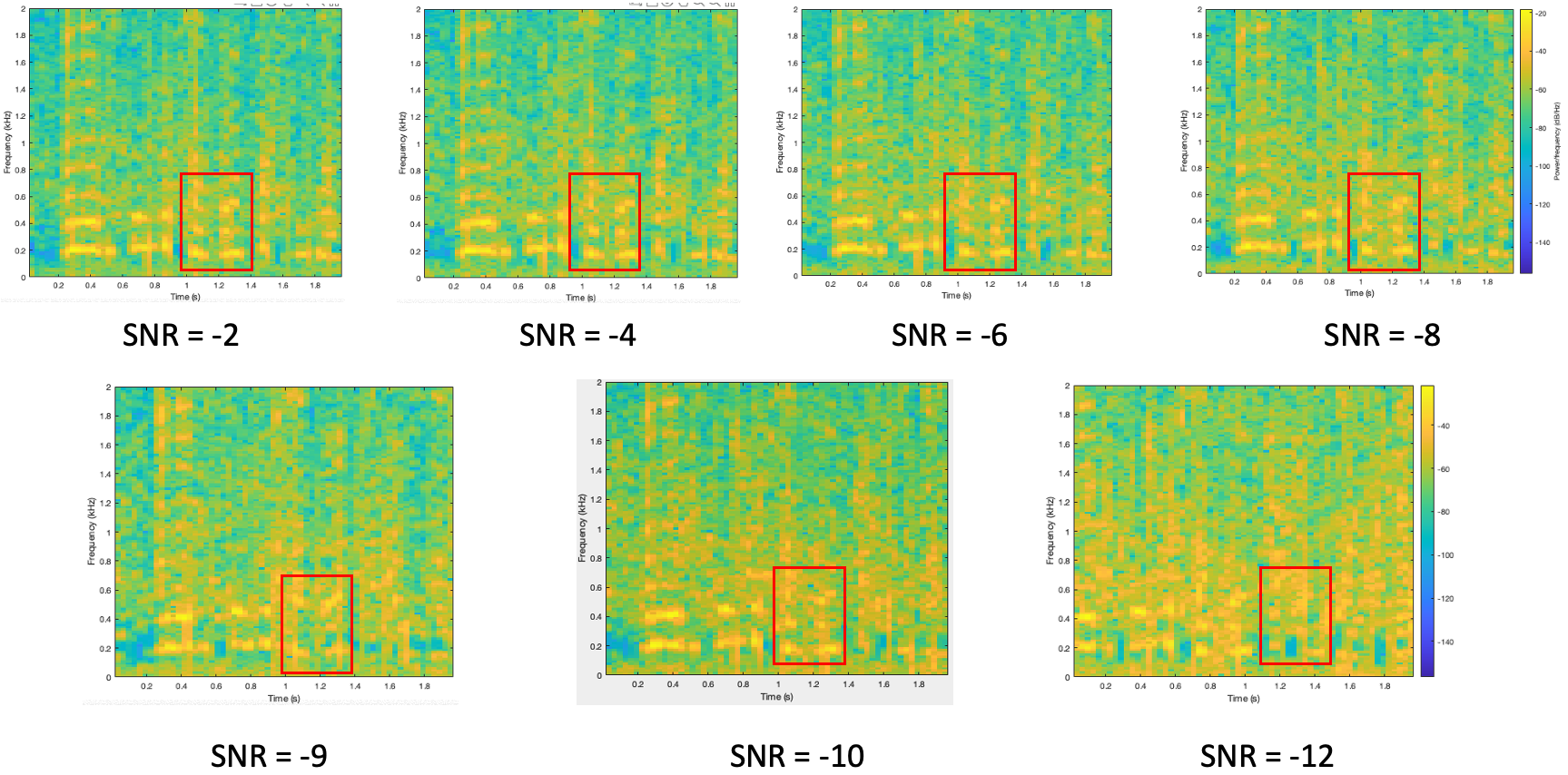
The following figure shows the spectrogram of the first 2 seconds of the retrieved audio (3570-5696-0000) under different obfuscation noise levels. And the red rectangle marks out some typical regions that indicates the effect of noise levels. With the increase of noise levels, the spectrogram becomes more blurred and noising, especially for the harmonic in voices, making the voice harder to be recognized.